Any given company could stop training tomorrow, and, as some others have said here, they'd be generating quite a bit of profit until their models visibly fell behind, however long that ended up taking, at which point they'd probably just fall over completely.
Over the whole industry? No; they can never, ever stop training, or they'll cease to be useful at all very soon.
Training is what keeps the models up-to-date on current events, which includes new programming languages, frameworks, and techniques. It's already been observed that using LLM assistance on some types of programming is much more effective than others, based on how well-represented they are in the training data: if everyone stopped training tomorrow, and next month a new programming language came out, none of them would ever be able to help you program in that new language.
This can be extended to other aspects of programming, too. If training stopped, coding assistants would gradually start giving you wrong answers on how to implement code for APIs, frameworks, and languages that continued to evolve, as they will always do, in much subtler (and likely harder-to-debug) ways than how they'd deal with a new language whose existence they don't even know about.
I don't know about others, but with Amazon specifically, it's always been very clear that their "losing money" in aggregate was purely on paper, for tax purposes: their ability to undercut everyone else was initially based on being online without the brick-and-mortar costs that other stores did, then on economies of scale, and now on being the 900kg juggernaut that just has more money than God and can blow it on running you out of business if they feel like it.
Frankly? That's Google's (well, Alphabet's, I guess) problem.
They're a multibillion-dollar international monopoly with absolutely staggering amounts of money and power, actively engaging in a wide variety of activities directly aimed at making the lives of every normal person on the planet worse so that they can have more power, more control, and more money. Me blocking ads on YouTube not only costs them effectively nothing, it's also the act of a flea against a polar bear.
If Alphabet showed any signs of actually wanting to create a sustainable alternative to the surveillance economy, I might have some sympathy for them. But not only do they not do this, they are the ones who created it in the first place.
I'm not sure where you got the idea that I'm boycotting "the ad-free model".
I'm boycotting them. After all, every cent that goes their way supports surveillance advertising (among other unsavory things).
I have other subscriptions that support ad-free creators.
If they choose to misconstrue my refusal to support them with either money or ad views, that's also their problem. (Also, that's patently never going to happen, because my signal vanishes instantly into the noise.)
Next, you have to have a clear path to reaching it.
Then, you have to have the resources to actually walk that path.
Only with all three of those can you make any credible claim that AGI is near.
As it stands, we have none of them—and the lack of the second is the most damning. It's very, very clear at this point that just scaling up the existing LLMs is not going to reach some critical mass and result in AGI, like the serendipitous sapience of Mycroft in The Moon Is A Harsh Mistress.
Given that, any path to AGI necessarily includes some new breakthrough on it (or more than one). And by their essential nature, breakthroughs are not something you can predict or schedule. Indeed, you cannot even be guaranteed that they will ever happen. (It is likely, assuming that it is physically possible to build AGI, that we will figure out how at some point...but not guaranteed.)
On the other hand approx human brain equivalence in computers has been predicted fairly accurately since about 1990 based on Moore's law type projections - mid 2020s by Moravec, 2029 by Kurzweil. The underlying assumption is once the hardware is widely available, hackers will hack something together.
But Moore's Law went out the window over a decade ago. Oh, sure, we're still getting things smaller and faster—but nowhere near the same rate we were before. Nowadays most (not all, but most) of the advances we're getting are in more and better parallelisation, rather than faster performance on each core.
And my (rough, limited) understanding is that based on much more recent projections, it would take several orders of magnitude more computing power to genuinely simulate a human brain than what we have.
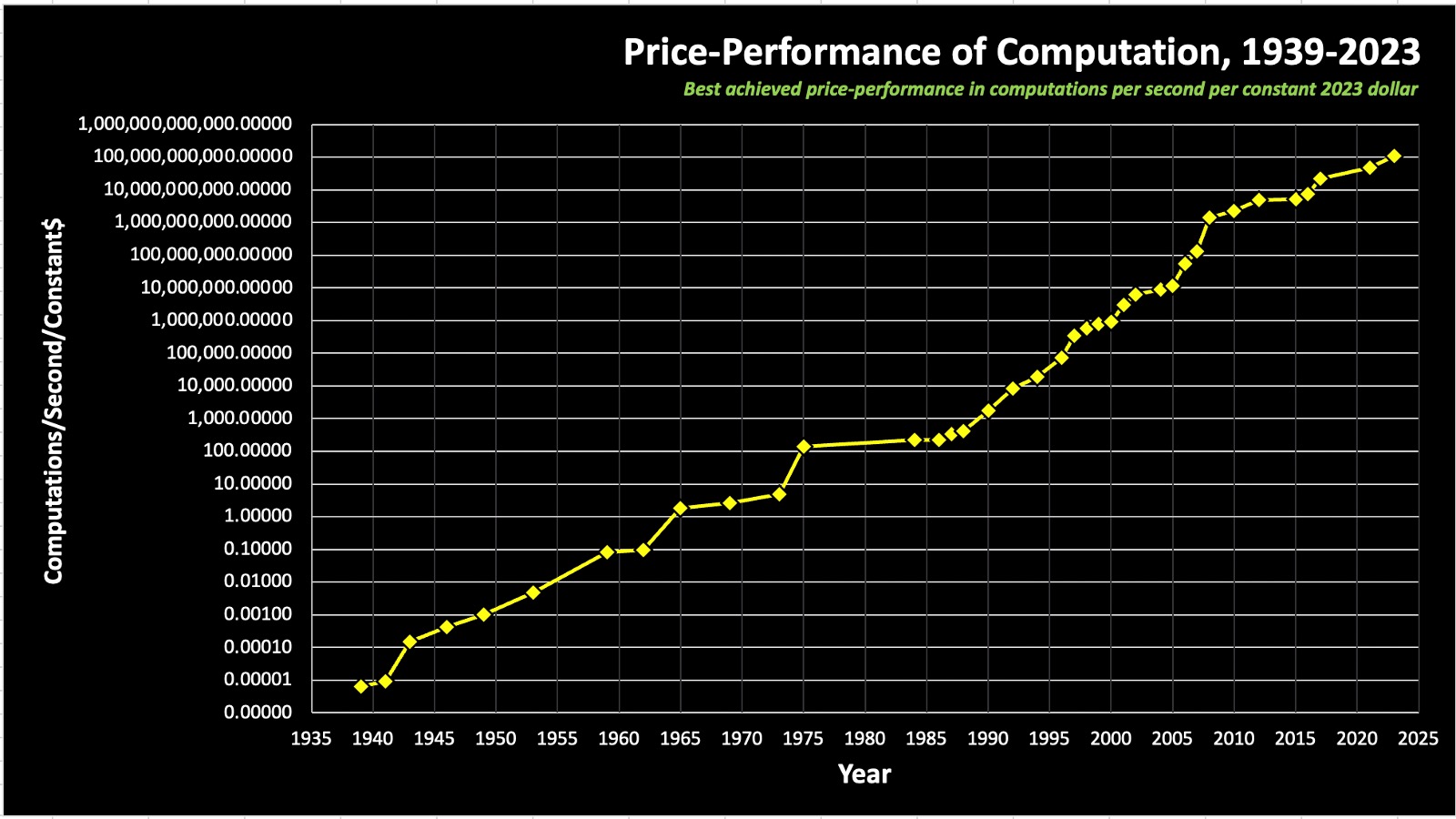
The main Moore's law like metric they track is compute in instructions per second, per dollar. That's kept on a fairly steady exponential for a century or so and doesn't seem to be slowing. (https://www.bvp.com/assets/uploads/2024/03/price-performance...)
We are probably not near simulating a brain but near enough for similar functionality. Moravec estimated it by looking at the retina which was fairly well understood and seeing how much compute was needed for similar object detection etc. in his robots.
The curve flattened out years ago. The exponential was going from GPT-2 to GPT-4 (or thereabouts). After that, it was painfully obvious to anyone observing without a vested interest in believing otherwise that the progress had slowed.
Now, it's not just that progress has slowed: it's that the exponential has reversed. In order to get marginal gains, they have to throw exponentially more hardware at the training.
Idk man… people have mostly decided they’re fine with sharing their data.
People use Google Maps even though their location is bought and sold openly. People put their deepest secrets into ChatGPT even after their CEO warned that they use it to sell you ads, keep all of it even after you delete it and may even be required to produce it during a lawsuit. People still buy new cars even though they track their movements.
What you feel is a deeply offensive ethical violation probably is fine with the general population. In general, people are willing to trade their data for good quality services.
What you're describing is "revealed preferences theory", and it requires a truly free set of choices—essentially, when looking at it in relation to companies like Google, it relies on "free market theory", the kind that only works with a spherical market in a frictionless vacuum.
People "have decided" this because they're not given good choices, they're not well-informed about what their data is going to be used for, and their real buying power has been going down for decades so they don't have the disposable funds to put toward the much more expensive options that would allow them to retain their privacy (even in the rare cases where such options still exist).
{kind=link}
Over the whole industry? No; they can never, ever stop training, or they'll cease to be useful at all very soon.
Training is what keeps the models up-to-date on current events, which includes new programming languages, frameworks, and techniques. It's already been observed that using LLM assistance on some types of programming is much more effective than others, based on how well-represented they are in the training data: if everyone stopped training tomorrow, and next month a new programming language came out, none of them would ever be able to help you program in that new language.
This can be extended to other aspects of programming, too. If training stopped, coding assistants would gradually start giving you wrong answers on how to implement code for APIs, frameworks, and languages that continued to evolve, as they will always do, in much subtler (and likely harder-to-debug) ways than how they'd deal with a new language whose existence they don't even know about.
reply